序言
我学英语的目标,并不是考试、证书,甚至也不是泛泛而谈的"交流能力"。
准确地说,我更想解决的是一个具体的问题:能不能无语言障碍地进入英语原生世界,直接阅读、收听、理解那些我真正感兴趣的内容。
如果目标是这个,那么很多常见的英语学习方法都会变得可疑。或许它们能帮助人通过某种评价体系,却未必能帮助人真正获得语言能力。
所以这篇文章绝不是一份方法清单,而是我对语言习得路径的个人梳理:
- 目标如何决定方法
- 输入为什么比技巧重要
- 阅读如何形成闭环
- 工具在实践中的位置
核心前提:目标决定一切
大多数人从未想清楚自己的目标是什么。 对于英语学习,当剥去应试的外壳后,还剩下什么?
我的目标:无障碍地进入英语原生世界
指英语材料本身逐渐变成可以直接使用的内容来源。
我希望达到的状态是:阅读、收听、理解原生内容时,语言不再是主要障碍,注意力可以更多落在内容、观点、情节和知识本身。
目标如何反推出所有方法选择
孤立的背诵10000个单词,甚至都不一定能让你看懂一个由5个简单单词组成,但是包含原生文化语境含义的句子。这注定我的目标与传统的只背单词,甚至是背课文式的阅读策略之间是不适配的。
关于应试惯性
其实本来写了一大堆对于应试体系的批判,但后来考虑,发觉和原本我想摒弃的一些陈词滥调的东西没什么不同。
观点停留在"它教得不好"——方法陈旧、内容脱离生活、考的不是真实能力云云。应当继续追问,然后呢?
再三考量后,觉得还是给一个简要的总结即可:如果这些方法都是在去拟合应试框架,那么一个最好结果也只是陷入到局部最优的情况。对于像是获取英语原生输入这样较开放的任务,其任务表现糟糕是必然的。
写给同样在思考这件事的人
把这些所谓的方法与建议单纯作为一件素材,一个观点样本,去做真正属于自己的思考和方法论的构建是真正有力量的。
可以有人代你去挖掘这些东西,但没人能帮你做选择。这就是更上一层,经过这样的转变后,事实上,很多原本无用的只看做技巧式的方法也能变成有价值的参考。
一、习得 vs 学得
Krashen框架的核心:可理解输入 + 潜意识习得
从工具的类比出发。对我这个目标而言,语言能力的核心更接近"习得",而不是单纯"学得"。
对比这样的两个过程:你尝试背下一个单词条目的15条内容释义。你进入了真实的文本。尝试让大脑去进行一个精确的搜索任务,并经历多个概念转换的过程。
另一种方式:你对于这个单词,你已经见过了有关它的几十条例句,覆盖了这个单词的所有具体用法。当你进入一个真实文本,你大脑进行的是联想活动,尝试进行语义推理,而不是精确的模式匹配。
这里的关键点就是,人类试图用一套复杂的像是语法机制、精确释义来尝试辅助语言学习,这在初期是有效和必要的。但某些体系认为这不够,甚至觉得不应该是辅助而是完全替代,忽略了其实大脑本身就自有一套真正高效的语言学习机制。
为什么这样说?不妨观察儿童习得母语的过程,这至少说明了,人脑具备一种从大量可理解输入中自动抽象语言模式的能力。成人二语学习当然不同,但这个机制仍然值得被认真利用,而不是被语法解释和背诵系统完全替代。
现在简述Krashen框架的核心,可理解输入:通过理解略高于当前水平的输入来习得语言。这是自然的,太难的看不懂,理解阻力过大;太简单则没有锻炼效果。
当然我不回避Krashen理论本身的争议性,但在输入获取的阅读侧:大量可理解的阅读输入对二语习得有实质帮助,和通过阅读发生的附带词汇习得是真实存在的观点是学界共识。 而我理解的关键点在于,这至少说明了:你给大脑输入海量的样例,专注在"理解内容上",所谓的"语法规则"是可以被自动处理和沉淀下来的。
为什么语法记忆不能替代习得
这里涉及到习得和学得的区别。依旧是简单的例子,当母语者流利的接收输入信息时,难道是用显式的知识进行语法分析,成分理解吗?显然不是,这是习得的能力。
而习得一门语言,或者说"获取"意味着,其在压力下是稳定的,就像是学会骑自行车后,你不能再感受那种不会骑的感觉。
当然,落到现实,必然有更多可辨析的机制和观点讨论。而在此处,我会更多地将其视作一个好的引子,展现语言学习其实是一个复杂的机制。
关于语言石化
如果语言主要依靠输入习得,那么输出就不应该被简单理解为"越早越好"。
这里需要先澄清一点:我并不是说初学者不能开口,也不是说早期写作一定有害。真正的问题在于,当一个人还没有足够的输入样本,却被迫长期输出时,他往往只能依靠母语翻译、语法规则拼接和固定模板来完成表达。
短期看,这能制造一种"我已经能用了"的流畅感;但长期看,这些临时策略可能会被反复强化,变成很难察觉、也很难修正的语言直觉。
所以我并不反对输出,而是反对把输出当作输入不足时的替代品。输出的价值在于暴露缺口、检验输入、建立反馈闭环。但它最好发生在一定输入积累之后,并且需要有修正机制。否则,输出练得越熟,可能只是把一套不自然的系统练得炉火纯青。
二、阅读闭环的设计
回落到我的实践过程,最终的产物其实是一个很简单的模型:
原生内容输入 → 上下文推断 → 延迟查词 → 语境制卡 → 间隔复习 → 回到原生输入
下文将详细展开介绍。
为什么选小说作为基础输入
小说之所以适合作为起点,不是因为小说天然更高级,而是因为它能提供连续情境。即使某些词不认识,人物、场景、动作、情绪会持续提供语义支架。
而走进实际的材料选择时,我发现了几乎绝佳的样本。一套我曾阅读过的完整小说:《无职转生》系列,内容量足够大,有二十多卷,且我本身就乐意再阅读一遍,结合我又对情节有足够的熟悉度,这极大地方便了我去尝试基于上下文的语义推理。
核心机制:习得的主动性必须在查询之前发生
基于saladict这样便捷易用的浏览器插件,可以实现完全无感的查词。
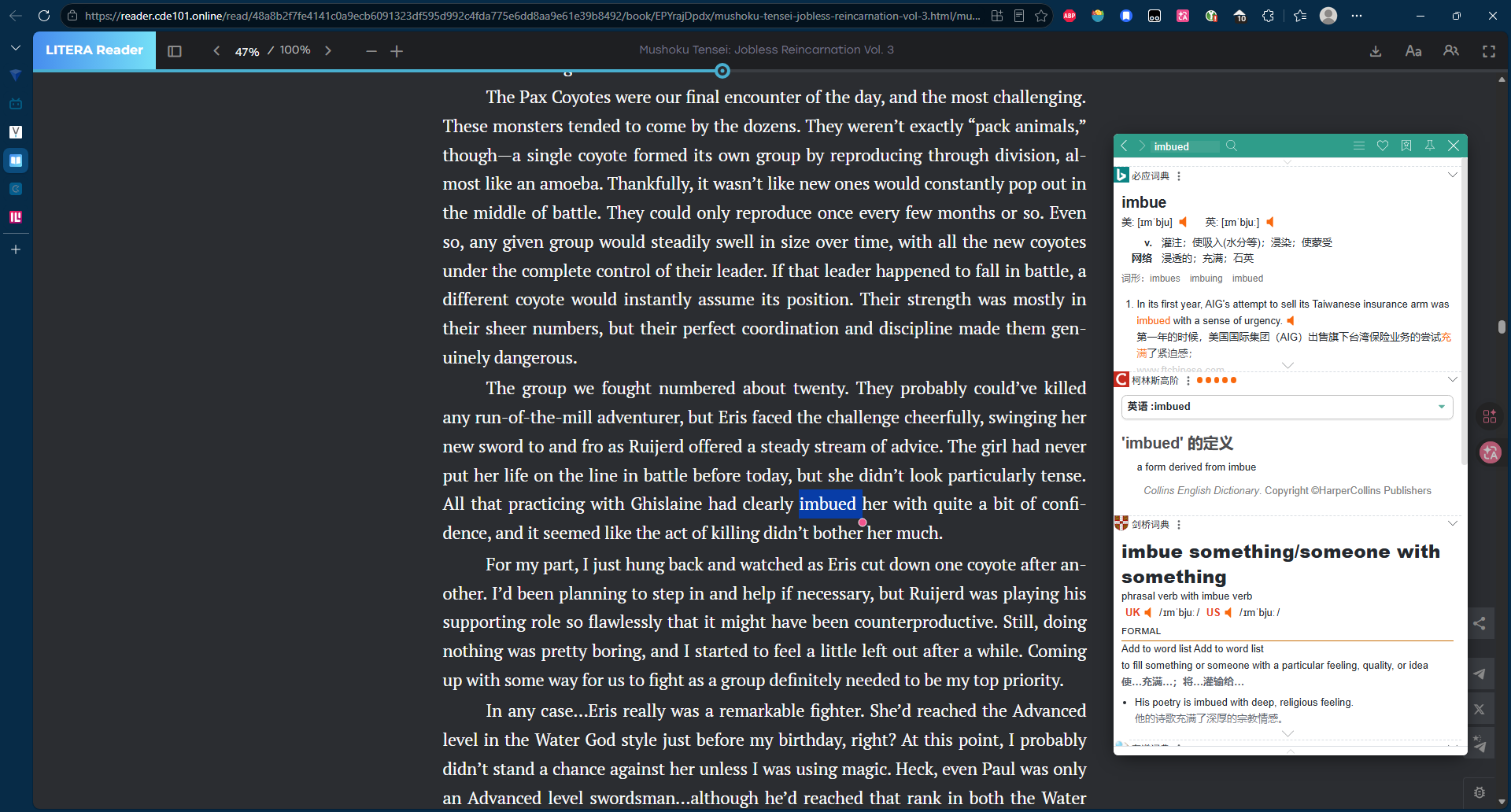
但是这里有值得警惕的部分:要优先保证阅读的流畅性。
我通常是这样做的,不论如何,先阅读完一整页,再回头审视那些注意到的生词。这时我或许可以根据上下文推断出它们的意思。当然没做到也是自然的,此时再进行查词过程。核心就是查询释义的过程:对于已经推断出释义的词汇,给到的是一个校对反馈;而对于陌生的词汇,其提供一个即时的印象。
关键点就在于,任何方法都不能让你自动获取语言能力。习得同样伴随着一个主动的模式,即你要尝试去"理解意义",结合上下文的语境。只是说在结合小说阅读的情景下,例如你知道某个角色在具体的场景下,他对谁做了怎样的动作,你很容易推出那个你并没有见过的动词的含义。
而这一切又发生在你在阅读小说,在看自己感兴趣的东西的背景下,是"自然发生"的。
Saladict + Anki的角色
此时我们再次审视anki这样的间隔重复工具,其意义就变成了:例如有个让你印象深刻的场景,其中恰有一个陌生单词在其中,使用间隔重复的方式,我们可以最大化程度的榨干其价值。
让我们进入一个实例。
注意我主要给出实际的流程参考,具体的实现细节在附录。
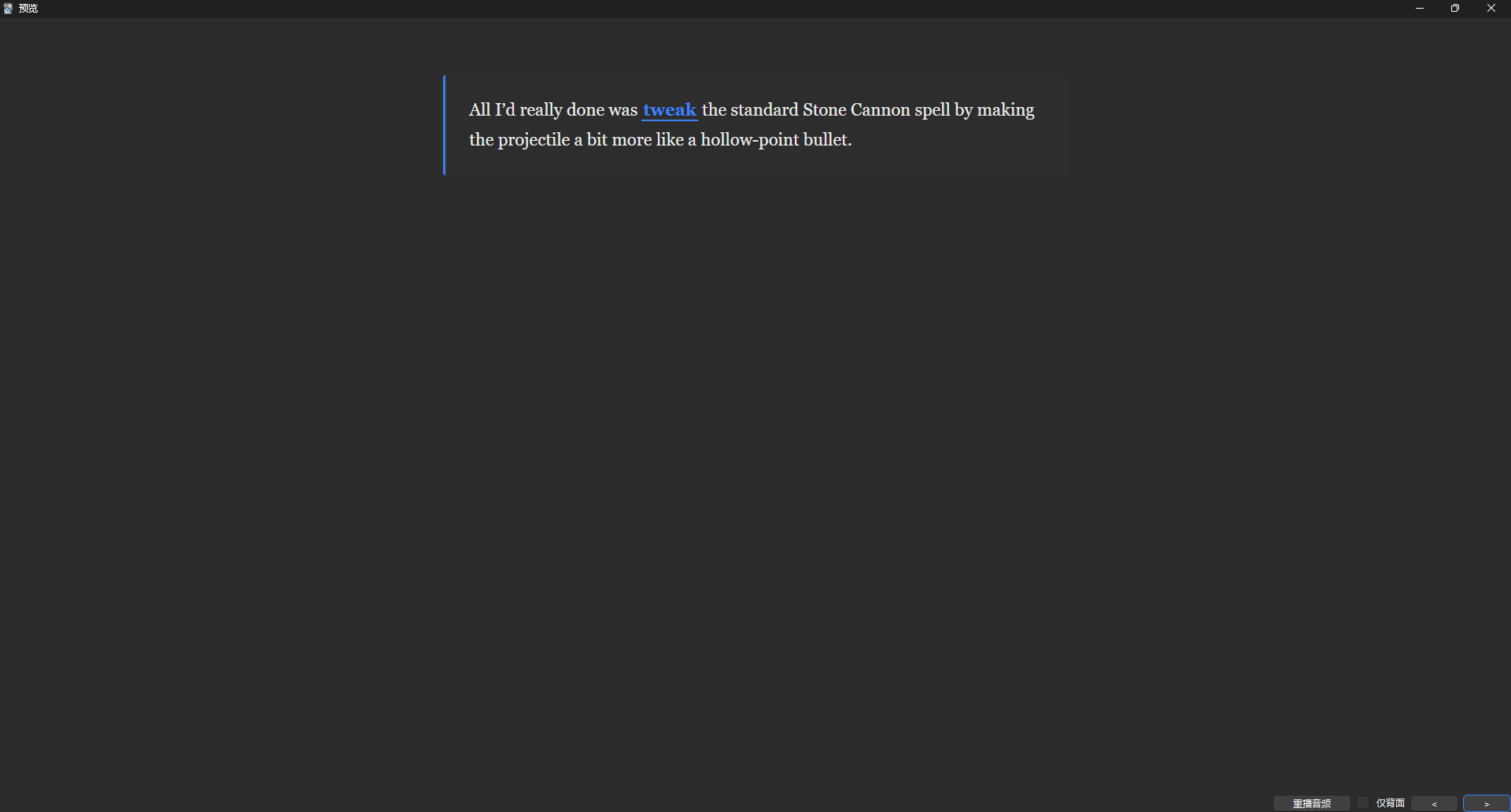
这里是一张卡牌的正面预览,包含了那个高亮的生词和完整的前后文句子。
"All I'd really done was tweak the standard Stone Cannon spell by making the projectile a bit more like a hollow-point bullet."
我尝试使用这里的例子讲解。 先同步我所处的状态,即除了这个生词外需要大致理解整个句子其余的意思。
"我所做的只是 ___ 标准的石炮法术,使弹丸更像空尖弹。"
这时我们会发现问题改变了,变得就像是小学生在学习母语时所做那类填词问题。而我们也只需做自然的猜测就好,即基于上下文推导这个词可能的含义。
在这里,其可能像是"改变","调整"之类的意思,不需要考虑什么,成分分析,语法上的判断,只需要从"理解"出发。
接下来翻到卡牌的背面预览。
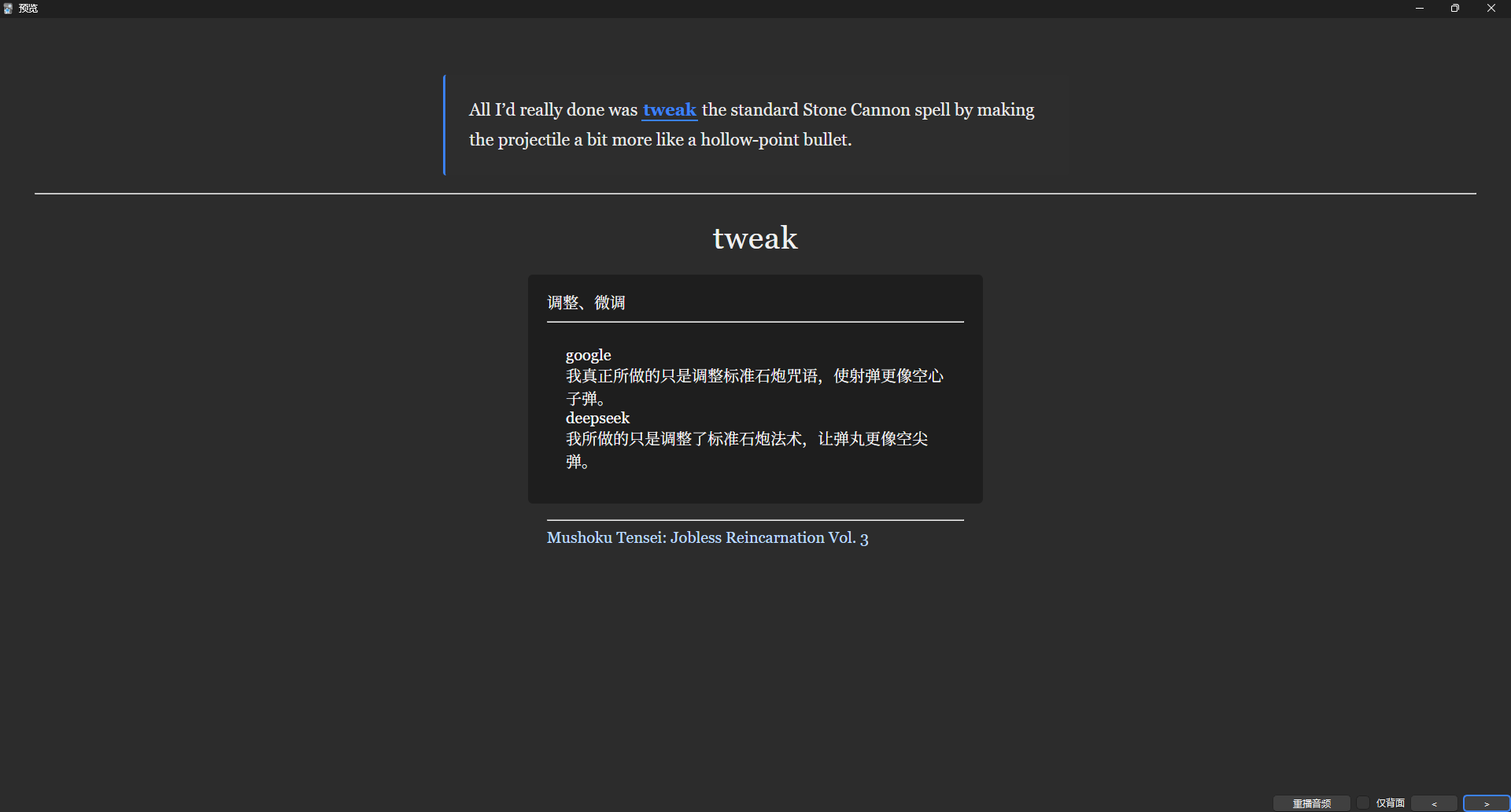
注意这里出现的释义,是基于上下文语境的,且保持了精简。然后是整句的释义。
其实在一般的复习中,当切换到背面后,会有四个按钮给你选择,详情可以了解FSRS算法,这里我不打算展开,但给出一个有趣的细节和参照:
- 通常如果我在直接看到高亮词汇的瞬间,就反应过来其含义的话,我会选择简单按钮
- 如果我是在结合上下文,或是回忆起场景才反应过来意思,我会选择良好按钮
- 如果结合上下文依旧不能判断其含义,需要翻转至背面查询,对应困难按钮
- 至于重来按钮,意味着对应在看到中文释义后,依旧是较陌生的,类似初见的状态,而实际上结合下文的讨论,这通常不会发生。
卡牌还提供翻页时高亮词汇的tts音频播放,这是anki自带的机制。
这里我要指出,像这样一张卡片的构建,在今天,完全可以以自动化,低摩擦的方式实现。即从我在真实文本中点击生词到一张这样的完整的卡牌,我只需要点击几个按钮。
当查词、制卡的摩擦如此之低,而且是基于web的内容源,事实上,你可以将任何材料拖入一个基于web的阅读器。也可以浏览任意英语世界的原生社媒平台,这引出了如下问题:这就意味着你得有"判断力",即该加什么词汇,而不是遇见任何生词就制成卡片。
或者务实一点,如果发现一张卡在查询界面,有TEM4/6之类的标注,就收录进生词本(没想到会在这里发挥作用)。
而关于我的做法,参考如下:
- 如果一个生词在文本中重复出现,且对其有略微的印象,哪怕只是一点点;
- 当从上下文能推导出含义,且推导正确的
- 一些关键的词汇,主导这个场景的人物行为理解的
- 反过来,我会注意排除那些一次性,孤立的词汇。
- 还有就是不要在此问题上纠结,如果你觉得这个词有意思,那就添加,没有什么不可。
阅读路径的阶段规划:小说→Reddit/Quora→专业文本
这里其实还有一个观点值得被讨论,就是泛读与精读。显然,小说类,虚构类的叙事文本适合泛读,因为其天然的上下文强相关且直观,适合建立解码的流畅度和做积累。
但当我们需要真正把语言作为一个工具时,不可避免的会进入更专业的文本,会更偏向"精读"。其实存在一个可供量化的指标即词汇覆盖率——流畅阅读的覆盖率约在95%-98%左右,低于这个值会更偏向每句话都要停下来,进行理解,因为其至少包含一个陌生词汇。
这里的安排不是绝对路径,如果你有一条贯穿的知识线,垂直领域很深,完全可以从专业文本出发。对应“使用英语学习,而不是学英语”的理念。其实这是理想的目标,既语言在这个过程中透明了。下文也将阐述另一个视角的观点,可能对你有启发。
三、路径与缺口
来看这样一个i+100的观点:
直接进入困难的,专业性强的文本。或许在最开始,你花费一整个下午。只推进了两页,但随着时间推移,会发现查询的词汇逐渐出现,阅读的流畅度渐进提升。或是一个星期或者更长,阅读完一本完整的专业性强的书籍。然后是继续阅读,选择相同领域的文本。本质上做的是在英语原生世界里破开一个缺口,并依托于此进行更广泛的输入获取。
其实有一个核心的观点博弈,即直接进行这样专业性强的文本阅读是困难的,且似乎违反了可理解输入理论。但这又是语言在使用中变得透明的实例,你在进行真实的学习活动,语言是附带的。下面是更多的分析。
同一个领域里的核心术语、论证结构、常见动词、抽象名词、句式模式会反复出现,其难度并不是无限扩散的,而是逐渐收敛的。前几十页可能极慢,但一旦你熬过最初的摩擦期,后面的阅读会明显加速。
其实就是 narrow reading(窄式阅读)。但结合本文基于实践的前提,这里不做引申。
所以问题的关键也在于边界的控制,这件事情其实有数个隐含的条件。
- 你对这个领域本身有强需求或强兴趣。
- 文本属于同一个领域,能形成高重复输入。
- 你允许自己一开始读得很慢。
- 你有工具辅助,比如词典。
- 你关注的是理解内容,而不是把每个句子都拆成语法题。
有什么启发吗——我觉得这不是观点的冲突,而是层级不同。可理解输入关注的是语言学习更底层的机制,而i+100 更关乎实际的可行路径。
这接上了上文关于阅读输入的路径选择部分。至于我为什么最后还是选择了从小说出发,也是基于实际情况的选择,无非是觉得积累太少太弱,先利用泛读文本提升基础的能力。
收尾
本文的目标不是又一个"方法分享"
我认为对所有的这些方法论必须要有一个警惕的姿态。
借用软件工程里的一句名言"No Silver Bullet"。
同时这里做出一个明确的边界提醒,即本文的内容是基于输入侧和阅读相关的。
关于听力和输出部分,我不会做更多的讨论,因为这既是我对内容质量的把关也是对读者的尊重,只讨论有实践的东西。
如同刚才谈到的,这篇文章只是引子。好的做法是在其基础上,结合你自身的实际情况给出自己的实践。
-
- 需求驱动决定优先级,而非外部标准
- 方法是原则的下游,不要本末倒置
- 习得是主动发生的,不是被动灌输的
附录:工具栈与css样式
saladict插件自带有ankiconnect支持,可以实现自动制卡。
结合anki的基于llm的插件,实现自动填充目标字段。且跨设备可用,至少我在安卓pad上(一般手机的屏幕太小,其实并不方便查词窗口同时显示),只需要安装一个提供支持第三方ankiconnect服务的开源软件,即实现了完整的流程。
我使用的anki字段自动填充插件名:AI Field Filler
安卓开源项目名:Ankiconnect Android
利用ankiweb的同步机制,双端可以流畅的切换。整个过程的开销就是llm的api调用开销,不过也是极低的。唯一美中不足的就是安卓原生的tts服务并不完善,导致在安卓平板上没有翻页语音。
- Literal Reader / ABSPlayer / Saladict / Anki
- AI生成内容实验
- 参考资料:罗萧尼系列视频、Krashen相关研究
卡片样式:
(正面)
<div id="text-container">
{{#ContextCloze}}
<section class="context-text">{{ContextCloze}}</section>
{{/ContextCloze}}
{{^ContextCloze}}
<h1>{{Text}}</h1>
{{/ContextCloze}}
</div>
<script>
(function() {
var container = document.getElementById('text-container');
if (container) {
var re = /\x7b\x7bc\d+::(.*?)(?:::.*)?\x7d\x7d/g;
container.innerHTML = container.innerHTML.replace(re, '<span class="cloze">$1</span>');
}
})();
</script>(背面)
{{FrontSide}}
<hr id="answer">
{{Audio}}
<h1>{{Text}}</h1>
{{#Meaning}}{{#Translation}}
<section class="trans">
<div class="note-content">{{Meaning}}</div>
<hr class="inner-divider">
<div class="trans_content secondary">{{Translation}}</div>
</section>
{{/Translation}}{{/Meaning}}
{{#Meaning}}{{^Translation}}
<section class="trans">
<div class="note-content">{{Meaning}}</div>
</section>
{{/Translation}}{{/Meaning}}
{{#Title}}
<section class="tsource">
<hr />
{{#Favicon}}<img src="{{Favicon}}" />{{/Favicon}}
<a href="{{Url}}">{{Title}}</a>
</section>
{{/Title}}
<script>
if (typeof Android !== 'undefined') {
// AnkiDroid原生TTS
setTimeout(function(){
AnkiDroidJS.ttsSpeak("{{Text}}", "en_US", 1.0);
}, 300);
} else {
// 桌面端
setTimeout(function(){
var u = new SpeechSynthesisUtterance("{{Text}}");
u.lang = 'en-US';
u.rate = 0.9;
speechSynthesis.speak(u);
}, 300);
}
</script>(css样式)
.card {
font-family: "Georgia", "Noto Serif SC", serif;
font-size: 20px;
text-align: left;
color: #e0e0e0;
background-color: #1a1a1a;
padding: 1.5em 1.2em; /* 稍微增加了四周的内边距 */
}
section { margin: 1em 0; }
/* =========================================
宽度比例控制 (正面 1.5 : 背面 1) - 放大1.2倍
========================================= */
/* 正面容器:较宽,作为视觉核心 */
#text-container, .context-text {
max-width: 795px;
margin-left: auto;
margin-right: auto;
}
/* 背面容器:较窄,作为辅助信息收拢在下方 */
.trans, .context-full, .note-box, .tsource, .audio-wrap, h1 {
max-width: 530px;
margin-left: auto;
margin-right: auto;
}
/* =========================================
具体样式定义
========================================= */
/* 正面:含上下文的收藏内容 */
.context-text {
font-size: 1.1em;
line-height: 1.7;
text-align: left;
color: #eaeaea;
background: #2d2d2d;
border-left: 3px solid #3b82f6;
padding: 1.2em 1.4em; /* 配合大屏,内部留白微调放大 */
border-radius: 4px;
}
/* 高亮的收藏词/短语 */
.cloze {
font-weight: bold;
color: #3b82f6;
border-bottom: 2px solid #3b82f6;
padding: 0 2px;
}
/* 背面主词 */
h1 {
font-size: 2em;
font-weight: normal;
letter-spacing: 0.02em;
margin: 0.8em auto 0.6em; /* 加大了与正面卡片的距离 */
color: #f0f0f0;
text-align: center;
}
/* 音频区域 */
.audio-wrap {
margin: 0.6em auto;
text-align: center;
}
/* 背面:翻译框 */
.trans {
border: none;
padding: 1em 1.2em;
text-align: left;
font-size: 1em;
background: #1e1e1e;
border-radius: 6px;
}
.trans_title {
display: block;
}
.note-content {
font-size: 1.05em;
text-align: center;
color: #e0e0e0;
padding-bottom: 0.6em;
}
.inner-divider {
border: none;
border-top: 1px solid #333;
margin: 0.4em 0;
}
.secondary {
font-size: 0.85em;
color: #888;
text-align: left;
}